Claude Code ソースコード解説シリーズ 第11章: Skill
Claude Code がタスク経験を再利用可能な Skill にまとめ、実行時に読み込む仕組みを解説します。
『Claude Code ソースコード解析シリーズ』第11章|Skill
前回 MCP を取り上げたことで、Claude Code がどのように外部ツール・外部リソース・外部サービスを自らのランタイムに取り込むのかが見えてきた。
しかし、ここでもう一つ未解決の問題が残る。
ツールがすでにあるのに、なぜ Skill が必要なのか?
たとえば、ユーザーが次のように言ったとする。
この PR のコードレビューをしてほしい。ツール層は Read、Grep、Bash、GitHub MCP、ブラウザ、子 Agent を提供できる。しかし「PR をどうレビューするか」という行為そのものは、単一のツール呼び出しではなく、ひとまとまりの経験則である。
- まず diff の範囲を確認し、無関係なファイルに惑わされない。
- 次にコードスタイルではなく、振る舞いの変化に着目する。
- バグ、権限、データの一貫性、テストの抜け漏れを優先的に探す。
- 出力時は問題点を先に列挙し、その後に総評を述べる。
- リポジトリ固有のレビュー規約があれば、そちらを優先する。
これらをすべてメインの system prompt に詰め込めば、プロンプトは際限なく肥大化する。毎回ユーザーに繰り返し指示してもらうのでは体験が悪い。コードにハードコードしてしまうと、チームがフローを変えたいときに Claude Code のソースコードまで修正しなければならない。
Skill が解決するのは、まさにこの類の問題だ。
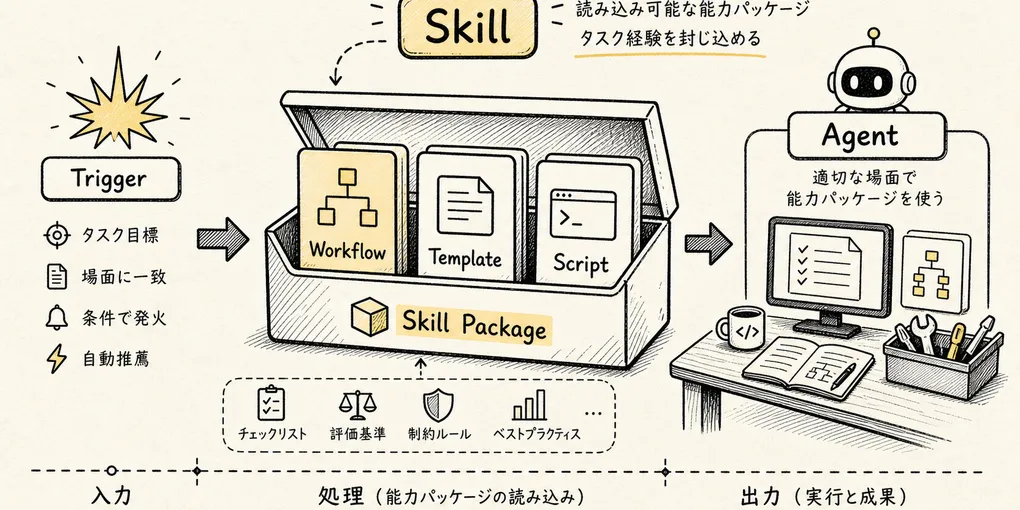
Skill とは、Claude Code に新たな低レベルツールを追加するのではなく、ある種のタスクに対する手順・制約・例・スクリプト・参考資料を、オンデマンドで読み込まれる能力パッケージとしてカプセル化する仕組みである。
この記事をより理解しやすくするために、一貫した具体例を据えておこう。
code-review スキルを作る。
ユーザーが「現在の変更をレビューして」と言えば、
Claude Code がチームの取り決めに従って diff を読み取り、リスクをチェックし、レビューコメントを出力する。本記事で答えようとする核心的な問いは、次の一点である。
Claude Code はどのようにして、ひとつの
SKILL.mdファイルから「モデルがそれをいつ使うべきかを知り、適切なタイミングで完全な説明を読み込む」という状態に至るのか?
1. なぜツールだけでは不十分なのか
「Tools」の章で述べたように、ツールシステムが解決するのは「モデルがどのように現実世界と接するか」という問題です。
しかしツールが答えるのは「何ができるか」だけであり、「どのように行うべきか」には答えません。
Read はファイルを読めますが、どのファイルを読むべきかはモデルに教えません。Bash はコマンドを実行できますが、テストを先に走らせるべきか diff を先に見るべきかは教えません。Grep は検索できますが、PR レビュー時に権限制御・データ書き込み・外部 API 呼び出しのどれを検索すべきかは教えません。
ツールをキッチンの包丁・コンロ・鍋にたとえるなら、Skill はレシピに近い存在です。
レシピそのものは食材を切ったり火をつけたりしませんが、以下のことを教えてくれます。
どのタイミングでこの包丁を使うか
どの材料から下ごしらえするか
省略してはいけない手順はどれか
失敗したときのリカバリー方法
最後の盛り付け方これを Claude Code に置き換えると、次のようになります。
Tools :Read / Grep / Bash / Edit / MCP
Skill :コードレビューのタスクに直面したとき、これらのツールをどう組み合わせ、どんな基準で結果を出力するかしたがって、Skill が生まれた本当の背景は「ツールが足りない」ことではなく、次の一点に尽きます。
ツールが増えれば増えるほど、モデルによるツールの使い方を制約する再利用可能な方法論の層が必要になる。
2. Skill とはシステム上何なのか
ファイル構成から見ると、Skill は通常 1 つのディレクトリであり、その中に SKILL.md が必須で含まれる。
.claude/skills/
└── code-review/
├── SKILL.md
├── review-checklist.md
├── examples/
│ └── finding-format.md
└── scripts/
└── collect-diff.shSKILL.md は 2 つの部分に分かれる。
---
name: code-review
description: Review code changes for bugs, regressions, security risks, and missing tests. Use when the user asks to review a diff, PR, or current changes.
allowed-tools: Read Grep Bash(git diff *) Bash(git status *)
---
# Code Review
## 3. Instructions
Review the current change as a senior engineer.
1. Inspect the diff before reading unrelated files.
2. Prioritize correctness, data integrity, security, and missing tests.
3. Report findings first, ordered by severity.
4. Keep summaries brief.
For detailed review criteria, read `review-checklist.md` only when needed.Frontmatter は Claude Code ランタイム向けのもので、本文はモデル向けのものである。
新しく公開されたソースコードを見ると、フロントマターには name、description、allowed-tools のような表示向けフィールドだけが含まれているわけではない。parseSkillFrontmatterFields() はより多くのフィールドを実行時設定としてパースする。たとえば次のようなものだ。
description
allowed-tools
model
effort
context: fork
agent
paths
hooks
user-invocable
disable-model-invocationこのうち context: fork は executionContext: "fork" に変換され、model や effort は Skill 発動後のモデル設定に影響し、paths は関連ファイルに到達して初めて Skill が出現するかどうかを制御する。つまり SKILL.md は単なる Markdown の断片ではなく、「本文+実行時境界」を宣言する能力記述なのだ。
その中で最も重要なのが description である。なぜなら Claude Code は、最初からすべての Skill の全文をコンテキストに詰め込んだりはしないからだ。まずモデルに渡されるのは、ごく軽量な「スキルカタログ」である。
Available skills:
- code-review: コード変更からバグ、リグレッション、セキュリティリスクを検出します...
- write-blog: 課題駆動型の技術コンセプトブログを執筆します...
- debug: バグを体系的に調査し修正します...モデルはまず名前と説明をもとに、その Skill を使うべきか判断する。実際に特定の Skill にヒットしたときだけ、Claude Code はその Skill の完全な内容を展開し、現在のタスクに注入する。
これが Skill の第一層の核となる設計である。
まずメタデータを公開し、ヒットしてから全文を読み込む。
これは要するにコンテキストエンジニアリングにおける「段階的開示」だ。すべての知識を一度にモデルに詰め込むのではなく、正しいタイミングで正しい指示を渡すのである。
4. 全体フロー:発見から実行まで
まず全体図を見てみましょう。
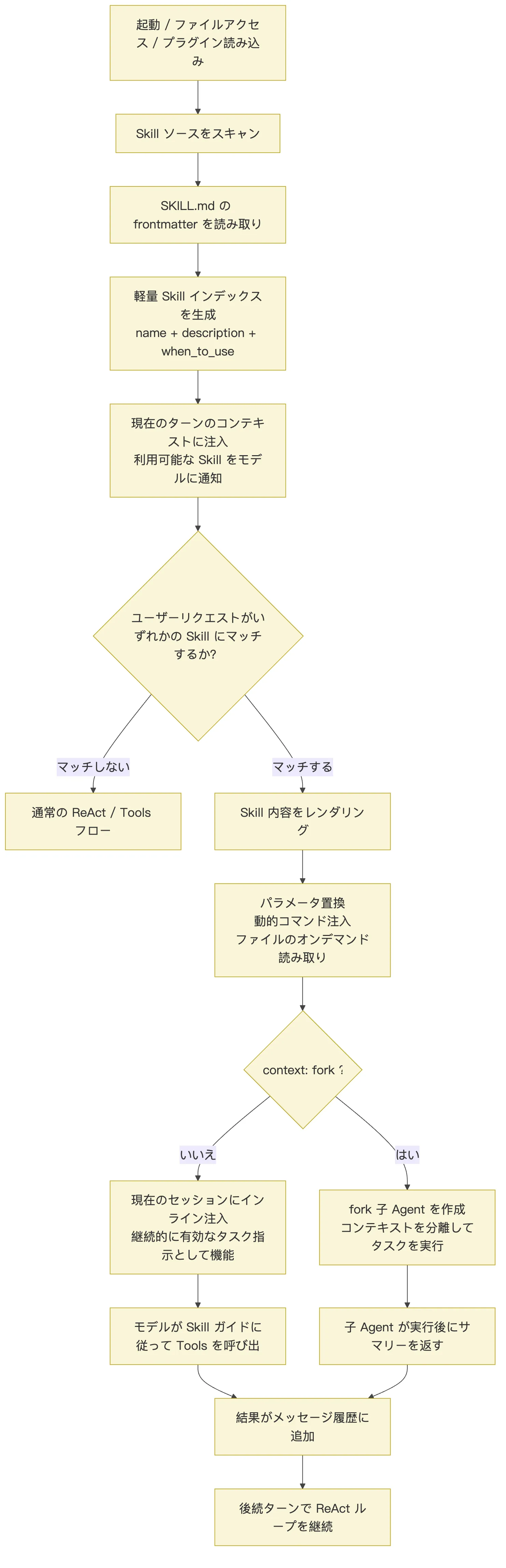
この図で最も誤解しやすいのは、最後の二つの経路です。
初期のソースコード解説の多くは、Skill を「SkillTool が子エージェントを fork する」と直接説明していました。この説明は一部のシナリオでは正しいものの、完全ではありません。現在の Claude Code の公式メカニズムでは、通常の Skill はデフォルトでインラインです。レンダリングされた SKILL.md が現在のセッションにメッセージとして注入され、後続のタスクでモデルに影響を与え続けます。
SKILL.md の frontmatter に次のように記述されている場合に限り:
context: forkClaude Code はその Skill を隔離されたタスクとして扱い、fork 子エージェントを作成して実行します。
したがって、より正確な理解は次のようになります:
通常の Skill:方法論を現在のコンテキストに注入する。
fork Skill:タスクを隔離された子エージェントに委譲して実行し、結果をメインセッションに持ち帰る。5. 読み込みレイヤー:Skill はどこから来るのか
Claude Code の Skill は単一のディレクトリだけを参照するわけではない。複数のレイヤーから収集される:
| 提供元 | 代表的なパス | 適した用途 |
|---|---|---|
| Enterprise / Managed | 管理者が配布するディレクトリ | 会社共通の規約、セキュリティフロー、コンプライアンスチェック |
| Personal | ~/.claude/skills/<skill-name>/SKILL.md | 個人用の定型作業、デバッグ、コミット、サマリ手順 |
| Project | .claude/skills/<skill-name>/SKILL.md | 当該リポジトリ固有の規約、スキャフォールド、アーキテクチャの取り決め |
| Plugin | <plugin>/skills/<skill-name>/SKILL.md | プラグインがパッケージとともに配布する機能 |
| Nested project | packages/foo/.claude/skills/ | モノレポ内の特定サブプロジェクト専用の機能 |
ソースコードレベルでより正確に言えば、getSkillDirCommands() は数種類の提供元を並列で読み込む:managed policy skills、user skills、project skills、--add-dir で指定されたディレクトリ配下の .claude/skills、そしてレガシー commands である。読み込み後は realpath による重複排除が行われ、シンボリックリンクや親ディレクトリの重複、互換パスによって同一の Skill が複数回登録されるのを防ぐ。
ここで見落としやすい境界ケースがある:--bare モードでは managed / user / project の自動検出がスキップされ、明示的に --add-dir で指定されたパスだけが読み込まれる。ただし、これはポリシーの回避策ではない。プロジェクト設定で Skill が無効化されている場合や、組織ポリシーで Skill がロックされている場合、bare モードであっても強制的に読み込まれることはない。
異なるレイヤーで同名の Skill が存在する場合、システムは上書き関係を処理する必要がある。公式ドキュメントに示された優先順位は次のとおりだ:エンタープライズレベルが最優先、次にパーソナルレベル、その次にプロジェクトレベル。プラグインの Skill は plugin-name:skill-name という名前空間を用いることで、通常の Skill との衝突を回避する。
もう一つ互換レイヤーが存在する。従来の .claude/commands/*.md が、現在は Skill と同じ仕組みで動作するようになっている。.claude/commands/deploy.md と .claude/skills/deploy/SKILL.md が両方存在する場合、Skill が優先される。これは、Claude Code が「スラッシュコマンド」と「スキルパッケージ」を単一のモデルに統合しつつあることを示している。ユーザーからは /deploy と見え、実行時には設定可能・ロード可能・管理可能な Skill として扱われる。
ソースコードから抽象化すると、おおよそ次のような形になる。
type SkillSource = "managed" | "personal" | "project" | "plugin" | "nested";
type LoadedSkill = {
name: string;
description: string;
path: string;
source: SkillSource;
frontmatter: SkillFrontmatter;
};
async function loadSkills(cwd: string): Promise<Map<string, LoadedSkill>> {
const roots = await collectSkillRoots(cwd);
const skills = new Map<string, LoadedSkill>();
for (const root of roots) {
for (const dir of await listSkillDirs(root.path)) {
const realPath = await fs.realpath(dir);
if (alreadyLoaded(realPath)) continue;
const skill = await parseSkillFile(`${dir}/SKILL.md`, root.source);
const key = namespaceSkillName(skill, root.source);
if (!skills.has(key) || hasHigherPriority(skill, skills.get(key)!)) {
skills.set(key, skill);
}
}
}
return skills;
}これは逐語的なソースコードリーディングではなく、ロードロジックを理解しやすい形に圧縮したものです。実際の実装では、ファイル監視、ポリシースイッチ、プラグインキャッシュ、パス重複排除、.gitignore フィルタリング、動的検出なども扱っています。
ここで特に重要なエンジニアリング上のポイントが二つあります。
第一に、realpath による重複排除です。同じ Skill ディレクトリがシンボリックリンクや多階層のディレクトリを通じて複数回スキャンされる可能性があるためです。実パスに変換しなければ、同一の Skill が重複して登録されてしまう恐れがあります。
第二に、ネストされたディレクトリの検出です。Claude Code は特定のファイルを操作する際、そのファイルパスを遡って .claude/skills/ を探します。これはモノレポにおいて非常に重要です。
repo/
├── packages/
│ ├── frontend/
│ │ └── .claude/skills/component-review/SKILL.md
│ └── backend/
│ └── .claude/skills/api-review/SKILL.md
└── .claude/skills/general-review/SKILL.mdモデルが packages/frontend/Button.tsx を編集しているときは、フロントエンド専用の Skill がより優先的に視野に入るべきです。packages/backend/routes.ts を編集しているときは、バックエンド API の Skill がより重要になります。
これは単に「スキャン対象ディレクトリを増やす」という話ではなく、コンテキストエンジニアリングの本質に踏み込んでいます。
Skill の可視性を現在の作業位置に関連付ける。
この背後にあるのが paths 条件付きアクティベーション機構です。paths フロントマターを持つ Skill は、必ずしも起動時に無条件 Skill(unconditional skills)に入るわけではなく、まずは条件付き Skill(conditional skills)に格納されます。セッション内で Read / Write / Edit といったパス関連の操作が発生した時点で、Claude Code がパスマッチングを行い、該当する Skill をアクティベートします。ネストされた .claude/skills を動的検出する際には、gitignored なディレクトリもスキップされるため、node_modules のような場所にある Skill が静かに能力プールに混入することはありません。
6. トリガー層:なぜ description が本文より重要なのか
Skill を書くとき、最もよくある失敗は本文を長々と書く一方で、description が実質的に空っぽというケースです。
description: Helps with code.この description はほぼ無意味です。モデルはこれを見ても、いつ読み込むべきか判断できません。
より良い書き方は、トリガー条件を盛り込むことです。
description: Review code changes for correctness, regressions, security risks, and missing tests. Use when the user asks to review a diff, PR, branch, or current uncommitted changes.この背景にある仕組みは、Skill の検出段階では、モデルは完全な本文ではなく軽量インデックスを見ている、という点にあります。
トリガー機構は次のようにイメージすると理解しやすいでしょう。
function buildSkillIndex(skills: LoadedSkill[]): string {
return skills
.filter((skill) => !skill.frontmatter.disableModelInvocation)
.map((skill) => {
const description = truncate(
[skill.description, skill.frontmatter.when_to_use].filter(Boolean).join("\n"),
1536,
);
return `- ${skill.name}: ${description}`;
})
.join("\n");
}ここで重要なのは具体的な数値ではなくメカニズムそのものです。Skill 一覧はコンテキスト予算の制約を受けます。description が長すぎれば切り詰められ、空っぽすぎればマッチしません。
つまり description は飾りではなく、モデルにとってのルーティングヒントなのです。
ソースコード内の SkillTool/prompt はさらにモデルを制約する。あるタスクが特定の Skill の恩恵を受ける場合、記憶に頼って直接実行するのではなく、まず Skill ツールを呼び出してロードすべきである。この点は重要だ。Skill の本文はデフォルトではコンテキストに含まれておらず、モデルが最初に見るのは Skill の名前と説明のみであり、実際にヒットした時点で SkillTool を通じて内容が新しいメッセージとして展開されるからだ。
優れた Skill の説明は、次の二つに同時に答えるべきである。
この Skill は何をするのか?
ユーザーがどのように言ったときに発動すべきか?単に「コードレビュー」とだけ書くと、モデルはそれが通常のレビューとどう違うのか判断できないかもしれない。一方で「ユーザーが PR のレビュー、diff のチェック、バグ探し、テストの網羅漏れの指摘を求めたときに使用する」と書けば、ヒット率は格段に安定する。
7. レンダリング層:Skill は静的な Markdown ではない
Skill がトリガーされると、Claude Code は単に SKILL.md の原文をコンテキストにコピーするのではなく、まず一回レンダリングを行う。
最も一般的なレンダリングは以下の 3 種類に分けられる。
1. パラメータ置換
ユーザーは次のように直接呼び出せる。
/fix-issue 123Skill にはこう書ける。
Fix GitHub issue $ARGUMENTS.
1. Read the issue description.
2. Find the affected code.
3. Implement the fix.
4. Add tests.レンダリング後、モデルが目にするのは次の内容になる。
Fix GitHub issue 123.位置パラメータも使える。
Migrate $ARGUMENTS[0] from $ARGUMENTS[1] to $ARGUMENTS[2].あるいは frontmatter で名前付きパラメータを定義する。
arguments: component from to本文にはこう書ける。
Migrate $component from $from to $to.2. 環境変数の置換
Skill は自身のディレクトリ内にあるスクリプトやテンプレートを参照することが多い。Skill は個人用ディレクトリ、プロジェクト用ディレクトリ、プラグイン用ディレクトリのいずれに置かれるかわからないため、絶対パスをハードコードできない。
そこで Claude Code は ${CLAUDE_SKILL_DIR} を提供している。
Run the helper script:
```bash
python3 ${CLAUDE_SKILL_DIR}/scripts/collect_diff.py .
```レンダリング時に、この変数は現在の Skill が存在するディレクトリに展開される。
3. 動的コンテキスト注入
Skill は !`command` を使うことで、モデルが内容を見る前にコマンドを実行し、その出力をプロンプトに埋め込むこともできる。
例:
---
name: summarize-changes
description: Summarize uncommitted git changes and flag risks.
allowed-tools: Bash(git diff *) Bash(git status *)
---
## 8. Current status
!`git status --short`
## 9. Current diff
!`git diff HEAD`
## 10. Instructions
Summarize the change and list risks.実行時、Claude Code はまず git status --short と git diff HEAD を実行し、その出力を展開して埋め込む。モデルが見るのはコマンドそのものではなく、展開済みの結果である。
これが有用なのは、「コンテキストの収集」を決定的なステップとして前倒しできる点にある。モデルが git diff を実行すべきか判断する必要はなく、Skill があらかじめテンプレートに組み込んでいる。
ただし、これにはセキュリティ境界も伴う。動的コマンドは本質的にシェルを実行する。信頼できないソースから取得した Skill に対して、あるいは企業がこうした機能をロックダウンしたい場合には、ポリシーによって無効化または制限しなければならない。
展開フローをコードに抽象化すると、おおよそ次のようになる。
async function renderSkill(skill: LoadedSkill, invocation: SkillInvocation) {
let content = await fs.readFile(skill.path, "utf8");
content = stripFrontmatter(content);
content = substituteArguments(content, invocation.arguments, skill.frontmatter.arguments);
content = content.replaceAll("${CLAUDE_SKILL_DIR}", path.dirname(skill.path));
content = content.replaceAll("${CLAUDE_SESSION_ID}", invocation.sessionId);
if (canExecuteInlineShell(skill.source, invocation.policy)) {
content = await expandBangCommands(content, {
cwd: invocation.cwd,
shell: skill.frontmatter.shell ?? "bash",
});
}
return content;
}これは、Skill が書き方はドキュメントに似ていても、実行時の振る舞いは「レンダリング可能なプロンプトテンプレート」に近いことを示しています。
11. 実行レイヤー:inline と fork は異なるセマンティクスを持つ
Skill がレンダリングされた後、Claude Code はそれをどこに配置するかを決定する。
デフォルトでは、現在のセッションにインライン展開される。つまり、Skill の内容は一つのメッセージとして現在の conversation に投入され、後続のツール呼び出し、モデルの応答、圧縮サマリーもすべてそれを中心に展開されていく。
新しいソースコードでは、このデフォルトパスがより明確になっている。SkillTool.call() はまず対応する command を探し、その command が prompt タイプかつ context === "fork" である場合にのみ、executeForkedSkill() に進む。それ以外の通常の Skill はスラッシュコマンドパイプラインを再利用し、processPromptSlashCommand() を呼び出して processedCommand.messages を取得した後、progress / command-message をフィルタリングし、現在の tool use id でメッセージにタグ付けし、最終的にこれらの newMessages を現在のセッションに書き戻す。
言い換えれば、通常の Skill は「ワーカーを起動する」のではなく、「処理済みのユーザーメッセージを現在のメインループに注入する」ものだ。context modifier を通じて権限、モデル、effort を一時的に変更できるが、実行するのはあくまで現在のセッションのメインモデルである。
inline に適した Skill は、通常「リファレンス型」または「規約型」だ。
---
name: api-conventions
description: API design conventions for this repository.
---これは Claude に次のように指示する。
When editing API endpoints:
- Use RESTful resource names.
- Return errors in `{ code, message }` format.
- Validate input at the boundary.この種の Skill は独立したタスクではなく、現在のタスクに対する背景ルールである。現在のセッション内に置くのが最も適している。
一方、context: fork は「タスク型」Skill に適しています。
---
name: deep-code-research
description: コードベースのトピックを徹底調査し、結果を返します。
context: fork
agent: Explore
---本文には次のように書きます。
$ARGUMENTS を徹底的に調査してください。
1. Glob と Grep で関連ファイルを特定します。
2. 実装を読み取ります。
3. ファイル参照を含めてアーキテクチャを要約します。
4. メイン会話で必要な結果のみを返します。この種の Skill は、入力と出力が明確で、かつ大量のファイルを読む可能性があります。fork によって子 Agent に分離することで、メインセッションが大量の検索詳細で汚染されるのを防げます。
実行レイヤーは次のように抽象化できます。
async function invokeSkill(skill: LoadedSkill, renderedContent: string, state: SessionState) {
if (skill.frontmatter.context === "fork") {
const agent = resolveAgent(skill.frontmatter.agent ?? "general-purpose");
return runSubagent({
agent,
prompt: renderedContent,
cwd: state.cwd,
includeClaudeMd: true,
});
}
state.messages.push({
role: "user",
content: renderedContent,
synthetic: true,
source: `skill:${skill.name}`,
});
return continueMainLoop(state);
}ここでの境界線は非常に重要です:
inline:Skill を現在のタスクの指示書として扱う。
fork:Skill を子 Agent に渡すタスク指示書として扱う。「API を書くときはこの規約に従う」だけの Skill に context: fork を設定すると、子 Agent はルールだけを受け取る形になり、明確なタスクがないため、有意義な結果を返せないことがほとんどです。
逆に、大量の検索・レビュー・レポート生成を行う Skill をメインセッションに inline で実行すると、中間処理の出力でメインコンテキストが肥大化してしまう可能性があります。
12. 権限レイヤー:allowed-tools は事前承認であり、サンドボックスではない
allowed-tools は「この Skill が使えるのはこれらのツールだけ」と誤解されやすい。
より正確には次のように言える:
allowed-toolsは Skill の有効化時に、これらのツールを事前承認することで、呼び出しのたびの確認を減らすものであり、それ以外のツールをシステムから削除するわけではない。
たとえば:
---
name: commit
description: Stage and commit the current changes.
disable-model-invocation: true
allowed-tools: Bash(git status *) Bash(git add *) Bash(git commit *)
---これは、ユーザーが手動で /commit を呼び出した場合、Claude が毎回確認を求めることなく、マッチする git コマンドを実行できることを表している。
ただし、あるツールを禁止したい場合は、allowed-tools だけに頼るのではなく、権限ルールの deny を使うべきだ。
Skill の実行自体も権限システムを通過する。SkillTool は /skill と skill という 2 つの書き方を正規化し、deny / allow ルールに従ってチェックを行う。ルールは完全一致のほか、review:* のようなプレフィックス一致にも対応している。おおまかな順序は次のとおりだ:deny にヒットすれば拒否、カノニカルなリモート Skill には特例があり、allow にヒットすれば許可、Skill が安全な属性のみを含む場合は自動実行、それ以外はユーザー確認に戻る。
つまり権限レイヤーは実際には二段階に分かれている。第一段階は「この Skill をロードできるか」を決定し、第二段階が Skill 有効化後のツール呼び出しに対する事前承認である。この二段階を混同すると、allowed-tools をサンドボックスだと誤解しやすくなる。
セキュリティの観点では、プロジェクトレベルの Skill はとくに注意が必要だ。.claude/skills/ はリポジトリにコミットできるため、他者がプロジェクトをクローンし、ワークスペースを信頼した場合、Skill 内の allowed-tools が実行権限に影響を及ぼす可能性がある。
したがって、Skill のセキュリティ境界は次の 3 行に圧縮できる:
description は、モデルがそれをいつ認識するかを決める。
SKILL.md の本文は、モデルがどう行動するかを決める。
allowed-tools は、どのツールが事前承認されるかを決める。この三つのいずれか一つでもスコープが広すぎると、スキルは危険なものになる。
13. Skill と MCP の違い
Skill と MCP はよく一緒に語られます。どちらも Claude Code の拡張機構だからです。
しかし、両者は同じレイヤーではありません。
MCP が解決するのは:
外部の能力をどうやって Claude Code に接続するか?たとえば Slack、GitHub、データベース、ブラウザ、デザインツールなどは、MCP server を通じてツール、リソース、プロンプトとして公開できます。
Skill が解決するのは:
接続された能力を、どうやって一連のタスクフローとして整理するか?たとえば「PR レビュー」では次のようなものを使うかもしれません:
- GitHub MCP で PR 情報を取得
Grepでコード検索Readでファイル確認Bashでテスト実行- プロジェクト内のレビューチェックリスト
これらをまとめ上げるのが Skill です。

ですから、Skill を MCP の代替と捉えるべきではありません。より適切な理解は次のとおりです:
MCP は外部世界を接続する。
Skill はそれらの能力を使って特定のタスクをどう遂行するかをモデルに教える。14. 最小実装:Skillランタイムを自作する
実装の考え方をより明確にするために、極小のSkillランタイムを書いてみましょう。Claude Codeが持つ完全な権限制御、UI、圧縮、サブエージェントといった機能は含まず、コアとなる連鎖だけを残したものです。
import fs from "node:fs/promises";
import path from "node:path";
import matter from "gray-matter";
type Skill = {
name: string;
description: string;
dir: string;
body: string;
};
export async function loadProjectSkills(cwd: string): Promise<Skill[]> {
const root = path.join(cwd, ".claude", "skills");
const entries = await fs.readdir(root, { withFileTypes: true }).catch(() => []);
const skills: Skill[] = [];
for (const entry of entries) {
if (!entry.isDirectory()) continue;
const dir = path.join(root, entry.name);
const file = path.join(dir, "SKILL.md");
const raw = await fs.readFile(file, "utf8").catch(() => null);
if (!raw) continue;
const parsed = matter(raw);
skills.push({
name: parsed.data.name ?? entry.name,
description: parsed.data.description ?? firstParagraph(parsed.content),
dir,
body: parsed.content,
});
}
return skills;
}
function firstParagraph(markdown: string) {
return markdown.trim().split(/\n\s*\n/)[0] ?? "";
}この部分は最初のステップだけを実行している。.claude/skills/*/SKILL.md をスキャンし、frontmatter を解析して、Skill の一覧を生成する。
第2ステップは、軽量なインデックスをモデルに渡すことだ。
export function buildAvailableSkillsPrompt(skills: Skill[]) {
return [
"Available skills:",
...skills.map((skill) => `- ${skill.name}: ${skill.description}`),
"",
"If a user request matches a skill, ask to load that skill before continuing.",
].join("\n");
}本物の Claude Code はこんなに簡素ではない。SkillTool を汎用ツール体系に組み込み、モデルが構造化された方法で Skill を呼び出せるようにしている。しかし、このミニマル版でも核となる考え方は十分に伝わる。
Skill の本文をすべてモデルに詰め込まないこと。
まずモデルに Skill インデックスを渡す。
ヒットしたら、対応する本文を読み込む。第3ステップは、特定の Skill をレンダリングする処理だ。
export function renderSkill(skill: Skill, args: string, sessionId: string) {
return skill.body
.replaceAll("$ARGUMENTS", args)
.replaceAll("${CLAUDE_SESSION_ID}", sessionId)
.replaceAll("${CLAUDE_SKILL_DIR}", skill.dir);
}第4ステップで、レンダリング後の内容をセッションに追加する。
messages.push({
role: "user",
content: renderSkill(skill, "review current diff", session.id),
});これが最小構成の Skill 機構だ。
Claude Code はこの基盤の上に、本番レベルの機能を積み上げている。
- 複数ソースからの読み込みと上書き
- ライブ変更検知(live change detection)
- ネストされたディレクトリの動的探索
pathsによる条件付き有効化allowed-toolsによる権限の事前承認disable-model-invocationとuser-invocablecontext: forkによるサブ Agent 分離- 動的シェル注入
- supporting files のオンデマンド読み取り
- コンパクション後の直近使用 Skill の再アタッチ
これらの機構は、Claude Code が独自に閉じたフォーマットを発明したものではない。公式ドキュメントにも明記されているとおり、Claude Code skills は Agent Skills open standard に準拠しており、その標準を拡張する形で自動呼び出し制御、サブ Agent 実行、動的コンテキスト注入といった機能を追加している。つまり、SKILL.md の基本形はオープンであり、Claude Code のエンジニアリング上の価値は、それを自前の QueryEngine、権限管理、コンテキストライフサイクルに接続した点にある。
ソースコードの実装には、もう一つエンジニアリング的に優れた選択がある。Skill は専用の実行 DSL を新たに発明するのではなく、prompt slash command のパイプラインを再利用しているのだ。SkillTool の input schema は args をサポートし、frontmatter でも argument-hint / arguments を宣言できる。legacy commands が Skill 候補セットに読み込まれるのも、これら二つの機構がすでに同一のコマンド処理チェーンへと収束しているからだ。
これらの機能が積み重なることで、Skill は「単なる prompt ファイル」から「ガバナンス可能な能力パッケージ」へと昇華する。
15. Skill のライフサイクル
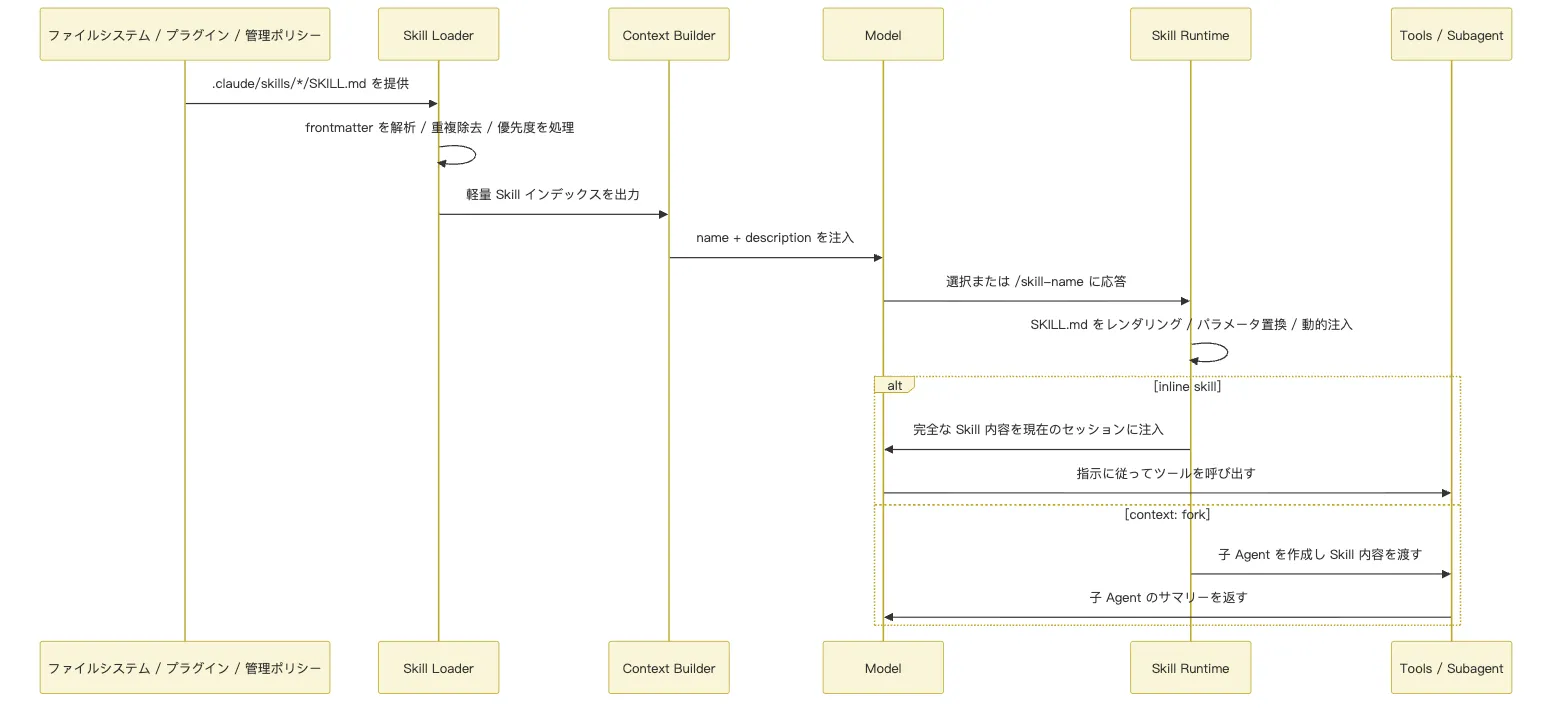
ここまでの内容を整理すると、Skill のライフサイクルは 6 つのステップに分けられます。
この一連の流れから、いくつかのよくある挙動を説明できます。
第一に、Skill を新規作成した後、再起動が必要な場合と不要な場合がある理由です。既存のディレクトリは監視対象になりますが、トップレベルのディレクトリが起動時に存在しなかった場合、再起動するまで watch の範囲に入らないことがあります。
第二に、Skill が発動しないときはまず description を修正すべき理由です。モデルが最初に目にするのはインデックスであり、全文ではないからです。
第三に、supporting files を SKILL.md にすべて書き込むべきではない理由です。Skill の価値はまさにオンデマンド読み込みにあり、メインファイルが目次ページのようになっているほど、長期のメンテナンスが容易になります。
第四に、context: fork を安易に使うべきではない理由です。これは「より高度なモード」ではなく、「隔離実行モード」です。タスクと成果物が明確に定義されている場合にのみ適しています。
16. Skill の設計思想
Claude Code の Skill システムは一見すると軽量だ。1つのディレクトリ、1つの Markdown ファイル、いくつかの frontmatter だけ。
しかし、その背後にあるエンジニアリング思想は重い。
1. 経験をプロンプトから切り離す
すべてのタスク経験をメインのプロンプトに詰め込んでしまうと、システムは保守しづらくなる一方だ。
Skill はこれらの経験を独立したファイルに切り出す。
ブログ執筆にはブログ執筆の Skill。
コードレビューにはコードレビューの Skill。
デバッグにはデバッグの Skill。
リリースにはリリースの Skill。これにより、チームはドキュメントをメンテナンスする感覚で Agent の振る舞いをメンテナンスできる。
2. コンテキストを「一括で詰め込む」から「必要に応じて展開する」へ
Skill の本質は Markdown ではなく、プログレッシブ・ディスクロージャー(段階的開示)にある。
モデルはまず短い説明だけを目にし、必要になった時点で完全な説明を参照する。さらに詳細なリファレンスやスクリプトは supporting files の中に置いたままにし、必要なときにだけ読み込むか実行する。
これは先の「コンテキスト管理」編で述べたことと同じだ。
優れた Agent とは、より多くを知っていることではなく、適切な瞬間に適切な情報を目にできることである。
3. 曖昧な判断はモデルに任せ、決定的な手順は資産として蓄積する
「このユーザーの発言はコードレビューを求めているのか」はモデルによる判断に任せるのが適している。
しかし「コードレビューではまず diff を見る、問題は重要度に応じて出力する、summary を findings より先に置いてはいけない」といったことは、Skill として蓄積すべきだ。
これも Agent エンジニアリングにおける重要な役割分担である。
意味的ルーティング:モデルに任せる。
安定したフロー:Skill に書く。
決定的な操作:ツールやスクリプトに任せる。
安全境界:パーミッションシステムに任せる。Skill はちょうどその中間に位置し、モデルとツール、コンテキスト、チームの経験をつなぎ合わせる役割を果たす。
17. 境界線:Skill が適さないこと
Skill は便利だが、すべてを詰め込めばいいというものではない。
第一に、Skill をデータベース代わりにしないこと。大規模な API ドキュメント、長大な仕様書、大量のサンプルコードは supporting files に置き、SKILL.md にはナビゲーションだけを書くべきだ。
第二に、高リスクな自動化をモデルの自動実行に委ねないこと。たとえば deploy、Slack 投稿、リソース削除、マイグレーション実行などは、次のように設定する:
disable-model-invocation: trueユーザーに明示的に /deploy を実行させるべきで、「コードの準備が整ったようだ、ついでにデプロイしておこう」とモデルに判断させてはいけない。
第三に、Skill を万能フローにしないこと。ひとつの Skill はひとつの明確なタスクを解決すべきだ。code-review、write-blog、debug はいずれも妥当だが、do-everything は新たなノイズ源になるのがオチだ。
第四に、権限を広く与えすぎないこと:
allowed-tools: Bash(*)これは Skill 有効時に過大な事前承認範囲を与えるのに等しい。高い信頼を置ける個人環境でもない限り、このような書き方は避けるべきだ。
18. Claude Code に戻る:Skill が埋めた最後のピース
ここで Claude Code の拡張レイヤーを改めて一枚の図にまとめてみよう。
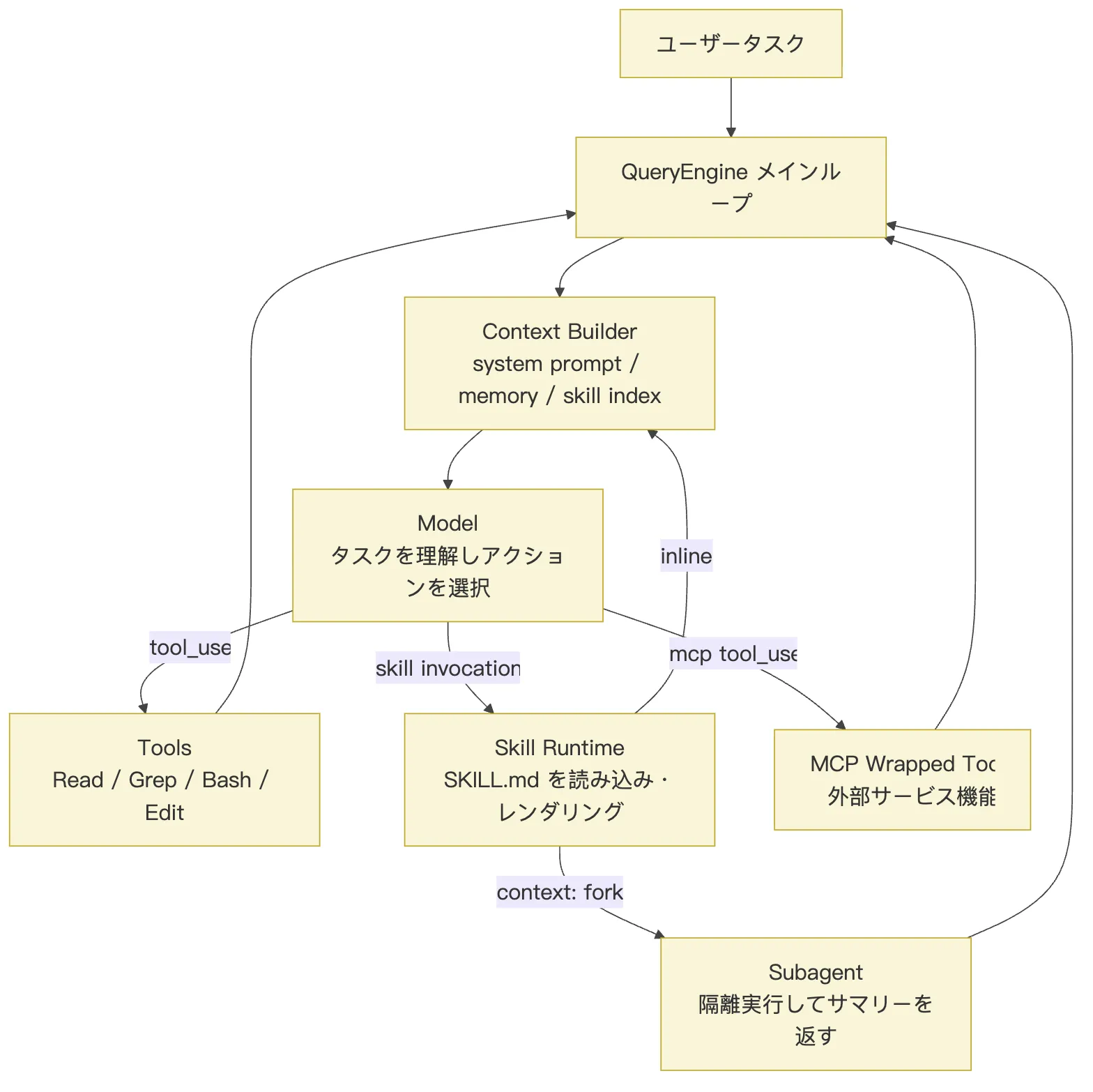
この図において、Skill は Tools や MCP と場所を取り合っているのではなく、別のピースを埋めている。
Tools → モデルに行動させる。
MCP → モデルを外部世界に接続する。
Subagent → タスクを隔離し、委譲する。
Skill → 経験を蓄積し、発見し、再利用し、必要に応じてロードする。つまり、Claude Code の Skill 実装において最も学ぶべきは SKILL.md というファイル形式ではなく、その背後にあるランタイムの階層構造だ。
- frontmatter による軽量なインデックス。
- description によるセマンティックルーティング。
- Markdown 本文によるタスク手法の記述。
- supporting files による詳細の遅延ロード。
- 動的注入によるリアルタイムなコンテキスト補完。
allowed-toolsとパーミッションシステムによるリスク管理。context: forkによる重いタスクの隔離。
この仕組みによって、Claude Code はすべての機能をメインプログラムにハードコードする必要も、すべての経験をメインプロンプトに詰め込む必要もなくなる。「ある種のタスクをどう実行するか」というノウハウを、チームでメンテナンス可能で、モデルが発見可能で、ランタイムで統制可能な資産へと変えているのだ。
これが Claude Code における Skill の本当の立ち位置である。
Skill はツールの代替品ではない。エージェントの作業方法をモジュール化してカプセル化したものだ。
このレイヤーを理解すれば、Claude Code の Prompt、Context、Tools、MCP、そして Agent の協調動作は、互いに無関係な概念の寄せ集めではなく、一つの目標に向かって協調していることが見えてくる。
モデルが、できるだけ少ないコンテキストの中で、ちょうど必要なだけの能力説明を受け取り、統制されたツールを使ってタスクを前に進めていくこと。